목차
0. 들어가며
1. RDS CPU 99% 이슈 발생 및 대응
2. RDS 인스턴스 타입 변경 이후에도 동일한 이슈 재발생
3. 또 다른 RDS 인스턴스의 비정상 지표 패턴
4. 작업전 지표와 작업후 지표 비교
5. 후속 대응 작업
6. 글을 마무리하며
0) 들어가며
2022년 당시 AWS 에 대해 무지했던 시기에 "서버 살려야한다.. AWS 배워야 한다." 라는
경각심을 일깨워준 좋은(?) 경험에 대한 내용을 정리해보았습니다.
-----
개발 인력의 퇴사와 더불어 사업 방향성이 웹에서 어플로 변경됨에 따라 어플의 출시와 신규 기능 개발 및 운영을 위해
Typescript 기반의 프론트/백엔드 개발 업무에서 어플의 백엔드 전담으로 업무가 변경 되었습니다.
신규 기능 배포 및 친구 초대 이벤트 홍보등 다양한 이슈로 인하여 신규 회원의 가입자 수가 폭발적으로 상승하는 때가 있었습니다.
그리고, 이 시기에 서버가 죽어버려 어플에 들어가면 홈 화면에서 무한로딩이 발생하게 되는 이슈가 발생하게 됩니다.
퇴근을 하고 지하철을 타기위해 지하철 게이트에 카드를 찍은 순간 걸려온 전화 한통..
"지금 APP 에 들어가면 무한 로딩이 되고 아무 기능도 쓸 수 없어요."
1) RDS CPU 99% 스파이크 발생 및 1차 대응
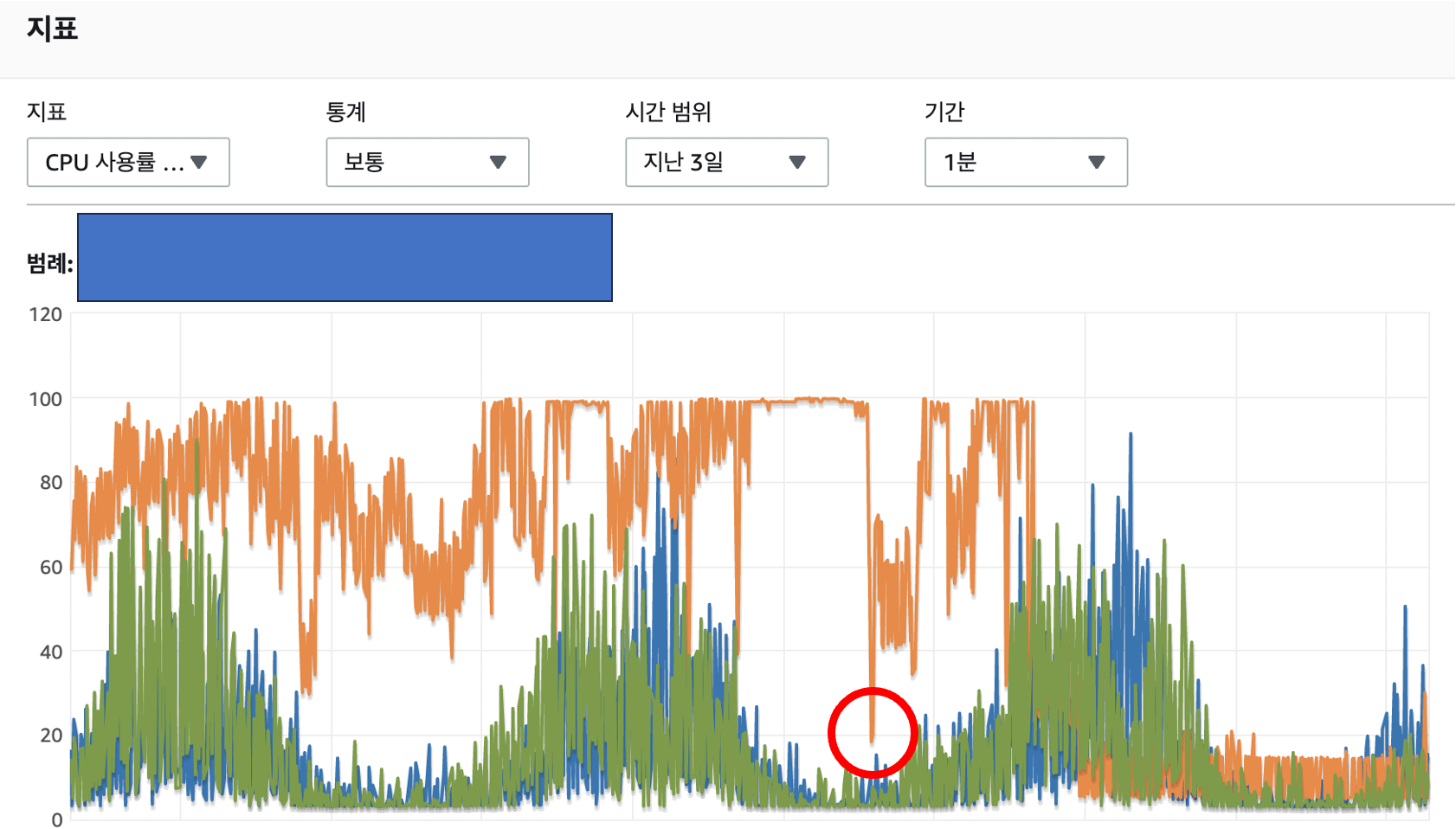
당시에는 AWS 에 대한 지식이 부족했기 때문에 RDS Performance Insight 에서 문제가 되는 쿼리와 테이블을 확인하고
RDS 의 DB 락을 풀고 문제가 되는 유저를 벤하는등의 자연스러운 프로세스를 진행하지는 못했습니다.
당시에 제가 문제를 파악하고 대응했던 방법은
1. 해당 서버가 배포된 AWS EC2 접속
2. docker swarm 의 형태로 배포된 서버의 로그 확인
3. 서버의 로그 확인 결과 API 요청에 대한 DB 쿼리 결과가 null 로 리턴되는것을 확인
4. 관계자에게 해당 내용 전달 및 대응
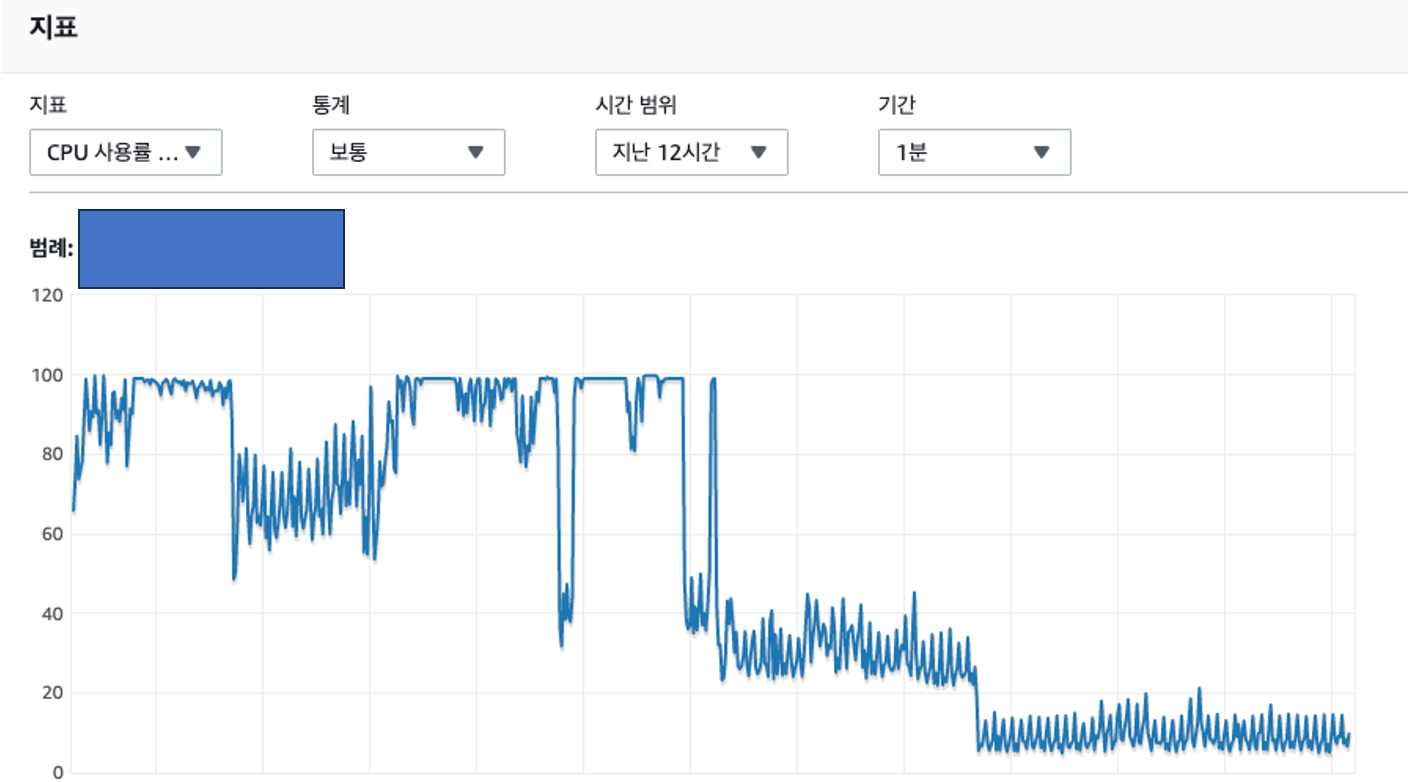
5. EC2 종료 ( 실제 운영중인 서비스에서 운영중인 서버를 꺼버린다는게 말이 안되었지만 무한로딩의 상태에서 사용자들의 지속적인 접속으로 인해 API 요청이 계속해서 쌓이고 DB 에 락된 쿼리들을 풀어도 다시 락이 걸려버려 이를 방지하기 위해 생각난 방법이 이것 밖에 없었다.. )
6. DB 트랜잭션 모니터링 ( select * from information_schema.innodb_trx; )
7. RDS 인스턴스 임시 업그레이드 ( large > xlarge )
8. AWS RDS CPU 점유율 모니터링
9. 락된 트랜잭션 해제 작업 진행
10. DB 테이블별 쿼리 통계 모니터링 ( select * from sys.schema_table_statistics )
11. 문제가 발생한 DB 테이블 및 쿼리 확인
12. 해당 쿼리의 userId 확인
13. 해당 유저의 API 요청 빈도수 확인 ( 룰렛 API 의 경우 평균 n 초를 정상 유저로 판단 )
14. 메크로 유저 판단 및 벤 처리
15. EC2 부팅
16. EC2 CPU 및 RDS CPU 점유율 모니터링
17. 경과 보고 및 문제 원인 공유
서버 재부팅 이후 한동안은 서버의 동작과 모니터링 지표가 정상범위내 머물렀기에 이슈가 어느정도 해결단계에 있다고 생각했었습니다. 하지만, 지표는 다시금 상승하기 시작했습니다.
2) RDS 인스턴스 타입 변경 이후에도 동일한 이슈 발생

처음 해당 이슈에 대한 노티를 전달받았을때 짐작되는 문제 원인 에는 크게 3가지가 있었습니다.
첫번째로 당시 어플에는 무제한으로 돌릴 수 있는 포인트 룰렛이 존재했고, 이로 인해 늘어난 어뷰징 유저로 인해 문제가 발생했다고 추측했습니다.
두번째로 어뷰징 유저로 인해 유저들의 포인트를 적립하는 테이블의 조회/생성 쿼리 성능에 문제가 있다고 추측했습니다.
세번째로 신규 유저들의 폭발적인 유입 대비 RDS 인스턴스의 처리 용량이 받춰주지 못하는것은 아닐까 추측했습니다.
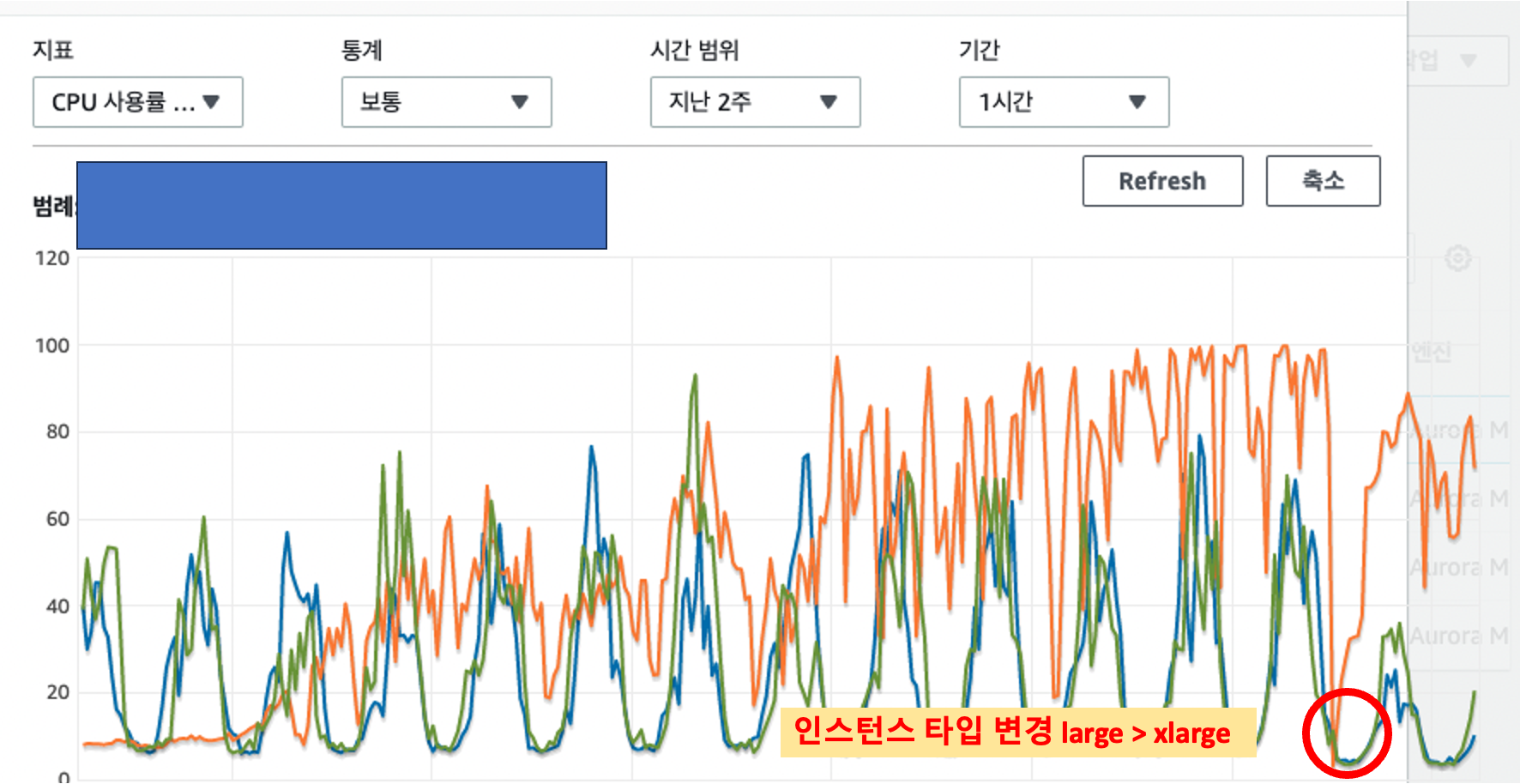
RDS 인스턴스 타입을 large > x.large 로 변경하였음에도 동일한 이슈가 재발생했기에 3번은 제외하고 나머지 원인들에 대한 확인 작업을 진행하였습니다.
이 과정에서 요청이 몰리는 엔드포인트의 쿼리 실행계획을 확인해본 결과 일부 조회 쿼리의 실행계획에 문제가 있는것을 확인 할 수 있었습니다.
실제 의도와는 다르게 조회 쿼리가 인덱스를 타고 있지 않았고, 불필요한 정렬과 필터링 그리고 급격하게 늘어난 row 로 인해 조회 성능이 떨어졌음을 확인 할 수 있었습니다. 로컬 환경에서 도커를 통해 mysql container 를 구동하고 prisma orm 을 사용해 schema migration 과 데이터 seed 작업 진행 후 로컬에서 다중 컬럼 인덱스를 추가하였을때의 실행계획이 기대와 동일하게 나오는지 1차적으로 확인하고 개발 서버에서 2차 확인후 실제 운영 서버의 DB 에 추가하는 작업을 진행하였습니다
다중 컬럼 인덱스 추가 후 지표가 정상 범위로 돌아오는것을 확인 할 수 있었습니다.
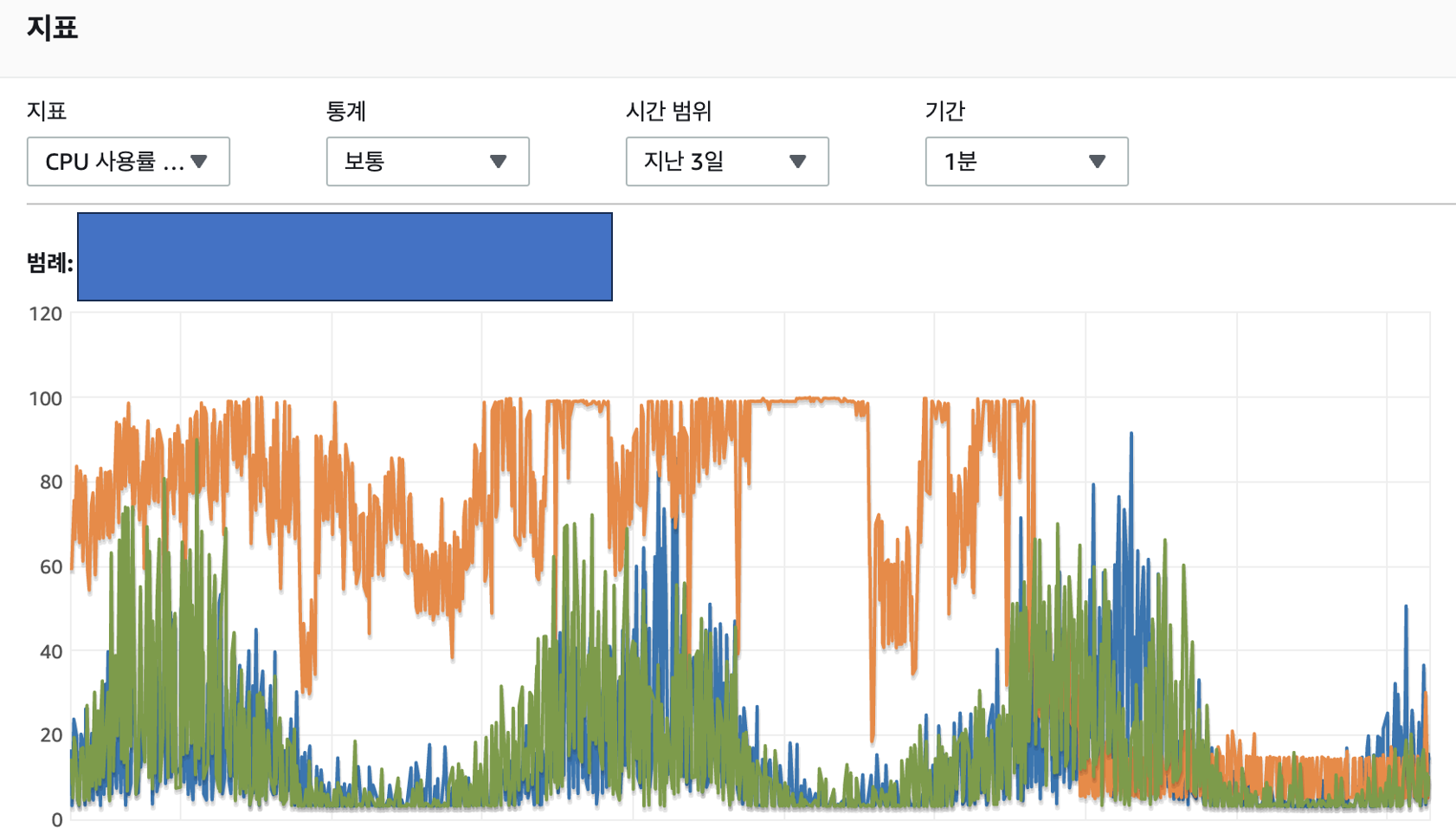
해당 작업으로 어플을 정상화 시킬 수 있었습니다.
3) 또 다른 RDS 인스턴스의 비정상 지표 패턴
이슈를 해결하고 다음날 출근해서 경과 확인을 위해 모니터링 지표를 체크하는 과정에서 문득 이상한점을 발견했습니다.
"분명 이슈는 해결했고 어플의 정상 동작도 확인했는데 패턴을 가진 초록색/파란색 RDS CPU 점유율은 뭘까"
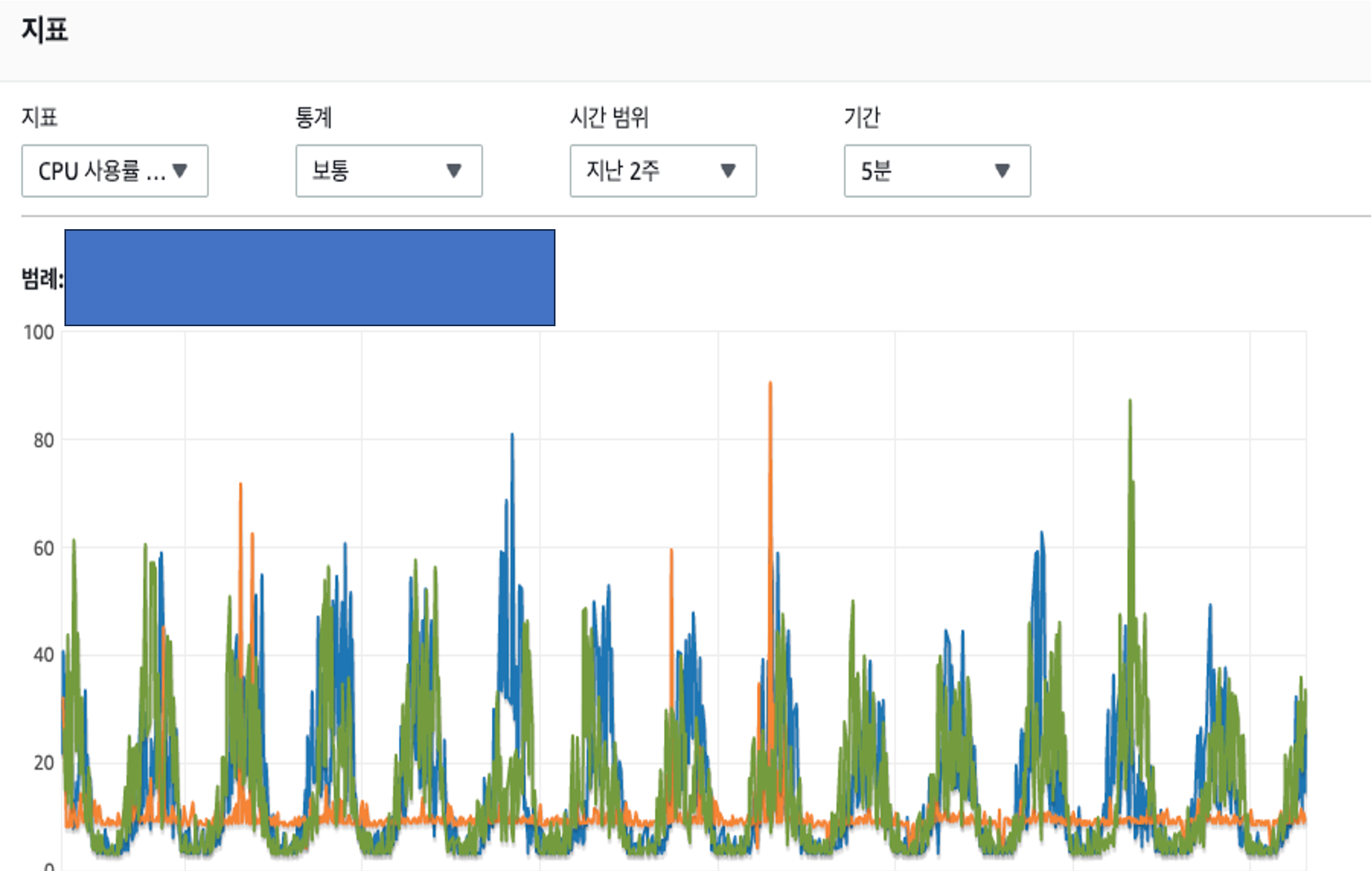
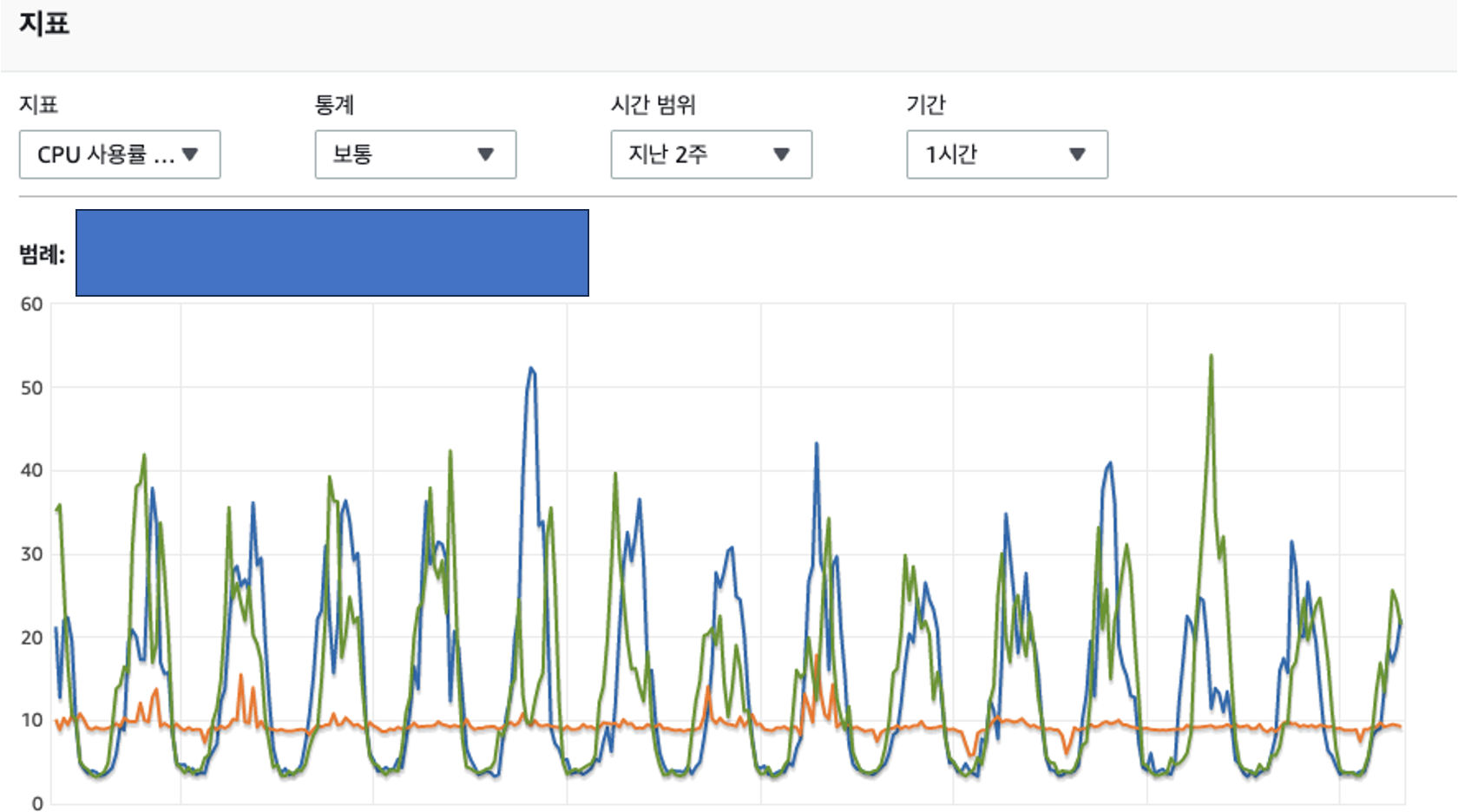
앞선 경험이 있었기에 비교적 간단하게 원인을 찾아 개선 작업을 진행 할 수 있었습니다.
지표상 나타나는 패턴이 반복된다는점에서 스케줄러로 추측 할 수 있었고, RDS Performance Insight 를 통해 특정 쿼리가 사용되는 스케줄러를 파악하여
개선 작업을 진행하여 최종적으로 스케줄러의 쿼리성능을 기존 11.11s 에서 1.79s 까지 단축할 수 있었습니다.
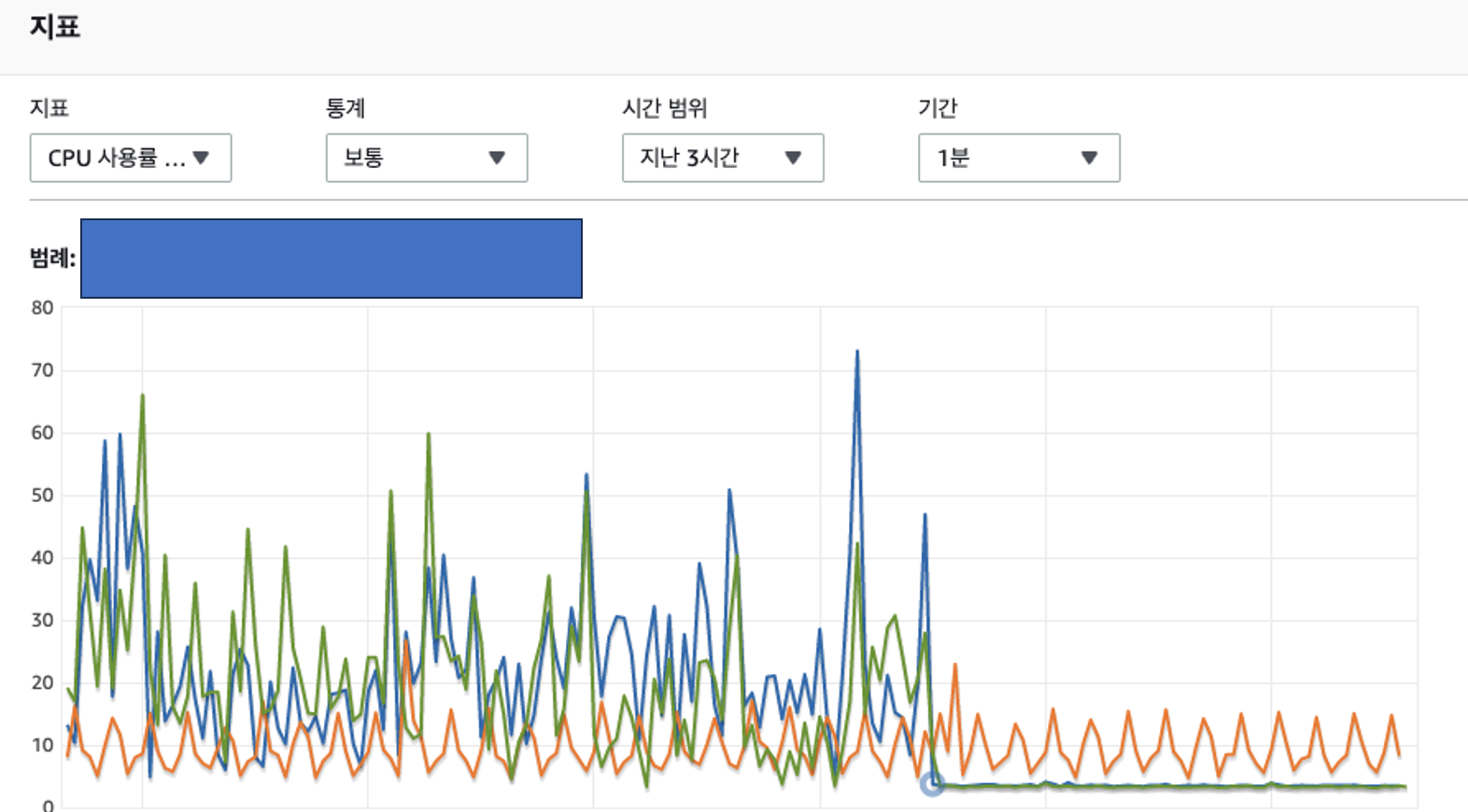
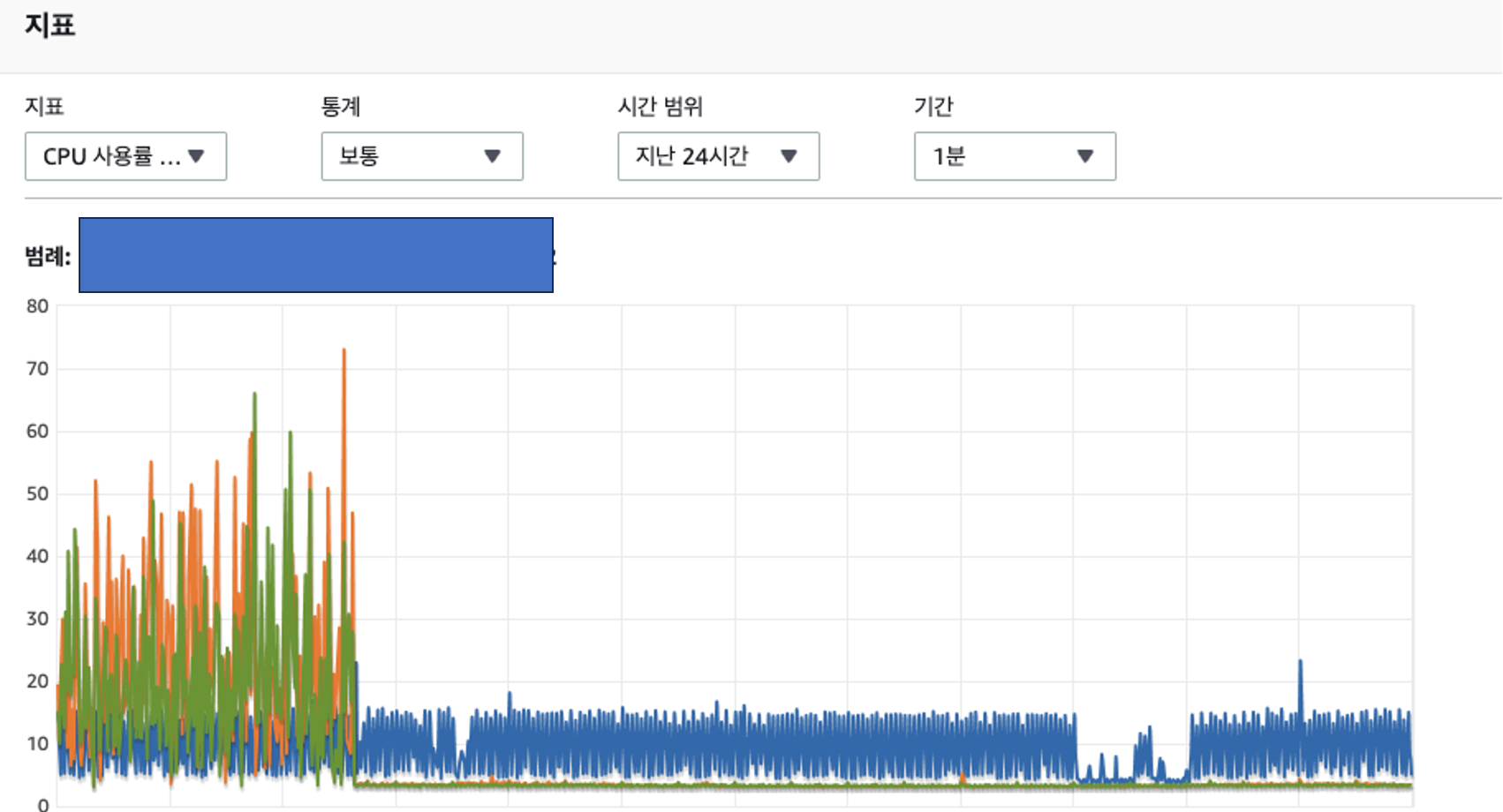
4) 작업전 지표와 작업후 지표 비교
개선작업을 통해 날뛰던 RDS CPU 점유율 지표를 개선할 수 있었고
작업전과 작업 후 CPU 점유율 지표가 눈에 띄게 줄어든것을 확인 할 수 있었습니다.
최종적으로 개선된 지표 경과는 아래와 같습니다.
표를 보실 때 대략적인 퍼센트만 표시한것을 감안해서 보시면 좋을 것 같습니다.
| RDS | 작업전 | 작업후 |
| Instance A | 40% ~ 99% | 5% ~ 약 25% |
| Instance B | 5% ~ 약 70% | 5% ~ 약 15% |
| Instance C | 5% ~ 약 70% | 5% ~ 약 15% |
5. 후속 대응 작업
서비스를 운영하며 이런 크리티컬한 이슈들을 CS 인입을 통해 알게되는것은 개발자의 간담을 서늘하게 하는 상황중 하나라고 생각 합니다. 추후에 이런 상황이 재발하는것을 막기 위해 아래 3가지 작업을 진행하였습니다.
첫번째로 Prometheus, Granfana 를 사용한 RDS CPU 모니터링 대시보드를 만들었습니다.
두번째로 Slow Query 가 발생하는 경우 Microsoft Teams 의 Slow Query Monitoring 채널로 메시지가 발송되게 만들었습니다.
세번째로 AWS CloudWatch RDS CPU Utilization 경보기능을 통해 RDS 의 CPU 점유율이 일정 퍼센트를 넘게되면, 메일이 전송되게 만들었습니다.
CloudWatch RDS CPU Utilization 경보 메일은 이후 서비스 운영과정에서 실제 발생 할 수 있는 이슈를 개발자에게 사전에 고지하는 역할을 톡톡히 했습니다.

6. 글을 마무리하며
저에게는 간담이 서늘했던 경험이었고 다시는 마주하고 싶지 않은 상황이지만
이를 통해 APM 구축의 중요성과 서버 운영에 대한 전반적인 경험, AWS 와 같은 인프라 구축, 쿼리 성능 개선 작업의 중요성을 배울 수 있는 기회였다고 지금은 생각 합니다.
제가 과거의 기억을 끄집어내 이 글을 작성하는 이유는
별다른 생각없이 썼던 n년전의 회고글을 지금 시점(2024)에서 다시 읽어보았을때 얻은 임팩트로 인해
과거의 경험을 퇴고하며 개발자로써 자신을 돌아보게 되는 계기가 되었기 때문 입니다.
더불어, 어딘가에서 과거의 저와 비슷한 문제를 맞닦뜨린 개발자들에게 조금이나마 도움이 되었으면 좋겠습니다.
긴글을 끝까지 읽어주셔서 감사합니다 :)
이만 글을 줄입니다.

'트러블 슈팅' 카테고리의 다른 글
| [AWS 트러블슈팅] AWS 운영 비용 절감하기 (0) | 2023.02.07 |
|---|

댓글